CG 2026
WallZero: Mastering the Game of WallGo with Strategic Analysis
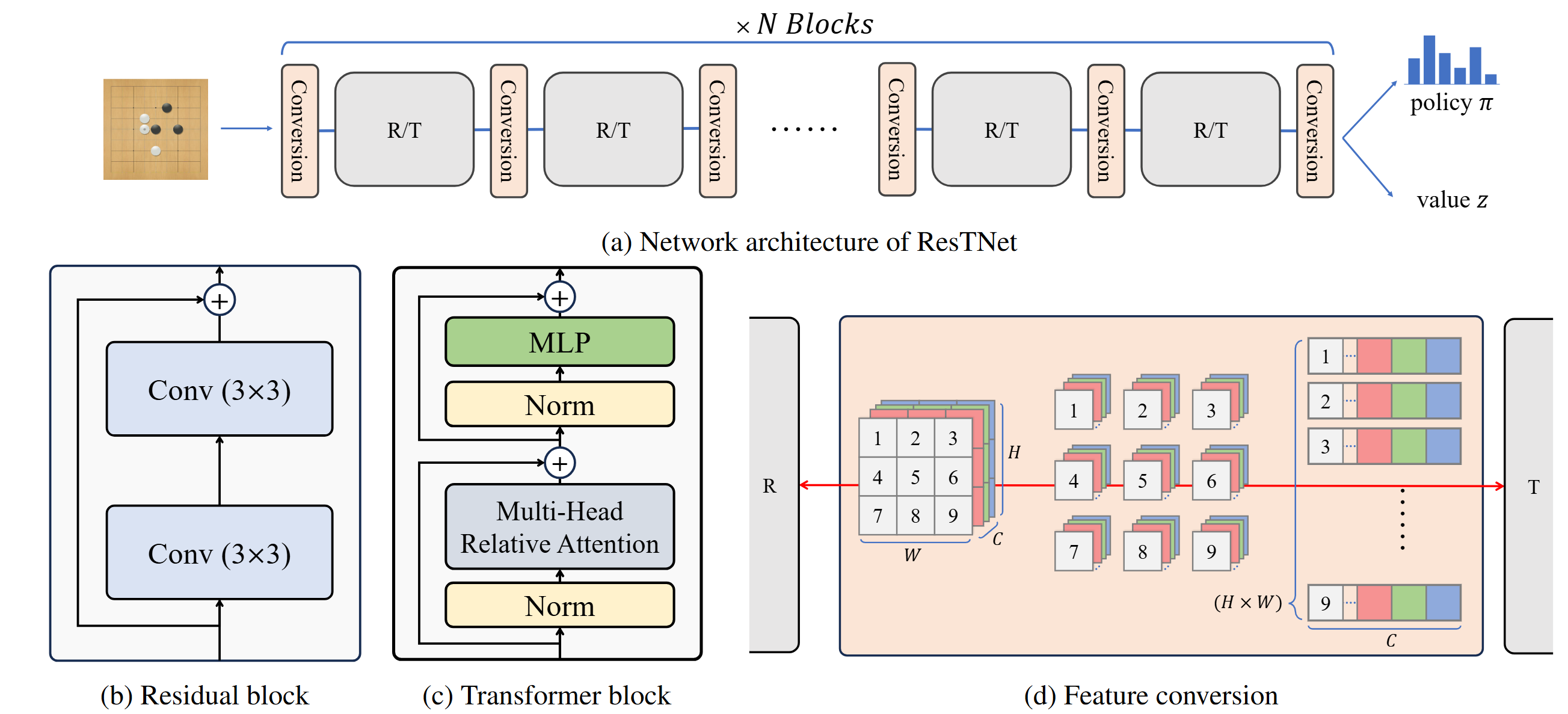
This paper presents WallZero, an AlphaZero-based agent for WallGo, a board game popularized by the Netflix series The Devil's Plan. WallZero defeats professional Go players and is further used to assess game fairness and identify key strategies for mastering WallGo.